资料参考:LearnRegex
应用场景
- 表单校验
- 字符串匹配和替换、解析(vue模板解析)
可视化工具:
1. 或者 |
js
const tel = '020-99999999'
console.log(/(010|020)-\d{8}/.test(tel))// true2. 原子表[]、原子组()
js
//原子表
let reg = /[123456]/ //出现在其中就匹配成功
console.log(reg.test("2")) //true
console.log(reg.test("9")) //false
//[()] [.+] 特殊符号放在原子表里就是普通符号(保留字符本意)
let str = 'www.baidu.com+'
console.log(str.match(/[.+]/gi)) //['.', '.', '+']
//原子组
let reg = /(34|56)/
console.log(reg.test("hdjfaks34fjj")) //true 满足组合才行
console.log(reg.test("hdjfaks35fjj")) //false3. 边界符^、$
js
let tel = "12020-99999999"
console.log(/^(010|020)\-\d{8}/.test(tel));//false 以010开头
let tel = "020-999999998"
console.log(/^(010|020)\-\d{8}$/.test(tel));//false 以8位数结尾4. 元字符

5. 匹配所有字符
js
/[\s\S]/
/[\d\D]/6. 模式修正符号i、g
js
const hd = 'djfkdjakDJFKJD'
hd.match(/[a-z]/gi)
// i 不区分大小写
// g 全局匹配
// m 每一行单独处理(^,$)检测字符串的开头或结尾,如果想要它在每行的开头和结尾生效,则用m
// u 宽字节匹配
// y 匹配完不匹配后面(提升效率)
// 字符属性
const hdstr = `dfa2332,hello! 正则表达式,哈!`
hdstr.match(/\p{sc=Han}/gu) // 按语言系统匹配中文 ['正', '则', '表', '达', '式', '哈']
hdstr.match(/\p{P}/gu) // 匹配所有标点符号 //[',', '!', ',', '!']
hdstr.match(/\p{L}/gu) // 匹配所有字母7. 原子组中的原子表([-\/])
js
let dateStr = '2022-08-30' 或 '2022/08/30'//true
let reg = /^\d{4}([-\/])\d{2}\1\d{2}/
console.log(reg.test('2022-08/30') //false
let reg1 = /^[a-z]\w{3,7}$/gi //校验用户名
let hhtml = `<h1>www.baidu.com</h1>
<h2>www.sougou.com</h2>`
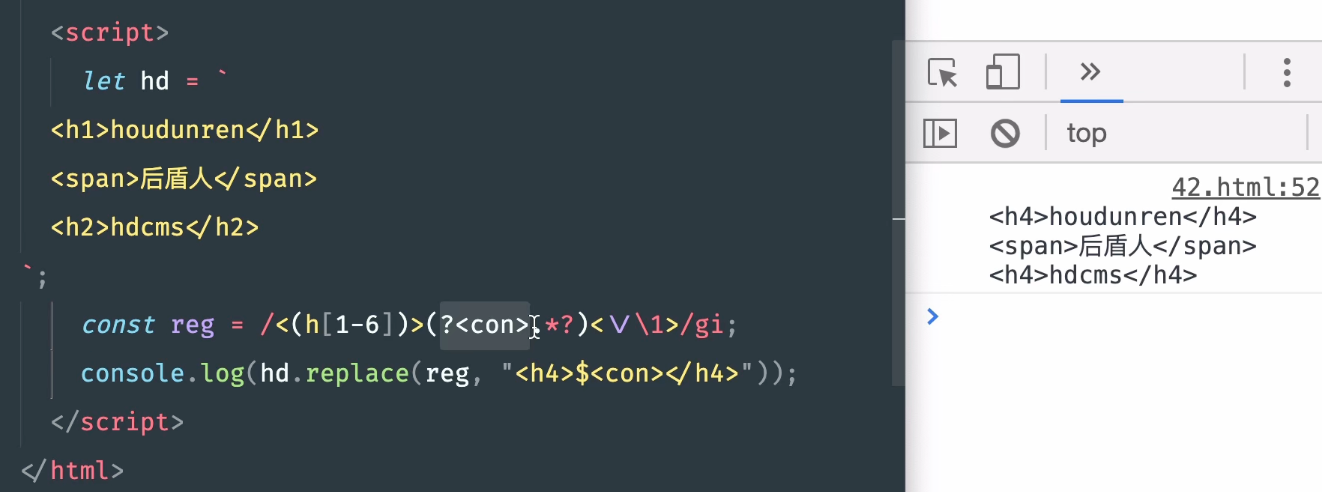
let reg = /<(h[1-6])>([\s\S]*)<\/\1>/i;
[
"<h1>www.baidu.com</h1>", //匹配到的第一个
"h1", //原子组1
"www.baidu.com" //原子组2
]
//替换操作
let res = hhtml.replace(reg,`<p>$1</p>`)
let res = hhtml.replace(reg,(p0,p1,p2)=>`<p>${p1}</p>`
$& //找到内容本身 (\0)
$` //内容前面的字符
$' //内容后面的字符
let reg = /<(h[1-6])>([\s\S]*)<\/\1>/gi; //全局匹配
[
"<h1>www.baidu.com</h1>",
"<h2>www.sougou.com</h2>"
]
let mailReg = /^\w[\w-]+@[\w]([\w-]+.)+(com|cn|cc|net|org)/
//不记录分组(?:) 原子组中使用?:则(match,exec输出结果中)不会记录此原子组8.贪婪匹配+、*、?
js
+ //一个或多个
* //0个或多个
? //0个或1个
{0,10} //0-10个
//禁止贪婪(往少的一方倾斜)
+? //一个 let reg = /(.*?at)/ ==> 'The fat cat sat on the mat. '.match(reg) ['The fat']
*? //匹配到一个就停止let reg = /(.*?at)/ ==> 'The fat cat sat on the mat. '.match(reg) ['The fat']
?? // let reg = /(.??at)/ ==> 'The fat cat sat on the mat. '.match(reg) ['fat']
{3,}? {3,10}? //3个
//案例练习
let html= `<span>www.baidu.com</span>
<span>www.map.baidu.com</span>
<span>www.know.baidu.com</span>`
let regbaidu = /<span>[\s\S]+<\/span>/ //贪婪到最后
let regbaidu1 = /<span>([\s\S]+?)<\/span>/gi
let newhtml= html.replace(regbaidu1,(v,p1)=> `<h2 style='color:red'>${p1}</h2>`)
//"<h2 style='color:red'>www.baidu.com</h2>\n<h2 style='color:red'>www.map.baidu.com</h2>\n<h2 style='color:red'>www.know.baidu.com</h2>"批量验证密码
js
let psdRegs = [/^[0-9a-z]{6,10}$/i,/[A-Z]/,/[0-9]/]
let result = psdRegs.every(reg => reg.test('fdkafad')) //false
let result = psdRegs.every(reg => reg.test('1f12aA')) //true9. matchAll
js
const hstr = `<h1>www.baidu.com</h1>
<h2>www.map.baidu.com</h2>
<h3>百度一下</h3>`
const breg = /<(h[1-6])>([\s\S]+)<\/\1>/gi
hstr.match(breg) // 全局匹配拿不到它每个原子组
// ['<h1>www.baidu.com</h1>', '<h2>www.map.baidu.com</h2>', '<h3>百度一下</h3>']
// 解决方法:使用matchAll
for (it of hstr.matchAll(breg)) {
console.dir(it)
content.push(it[2])
}
// 每个匹配项信息
[
'<h1>www.baidu.com</h1>',
'h1', // 原子组1
'www.baidu.com' // 原子组2
]
10. 断言匹配``
js
/* let reg = /百度(?=地图)/g
// 只有百度后面有地图两字的才满足要求
let htm = <p>百度一下,百度地图</p>
p.innerHTML.replace(reg,`<a href="www.map.baidu.com">$&</a>`)
?= //判断
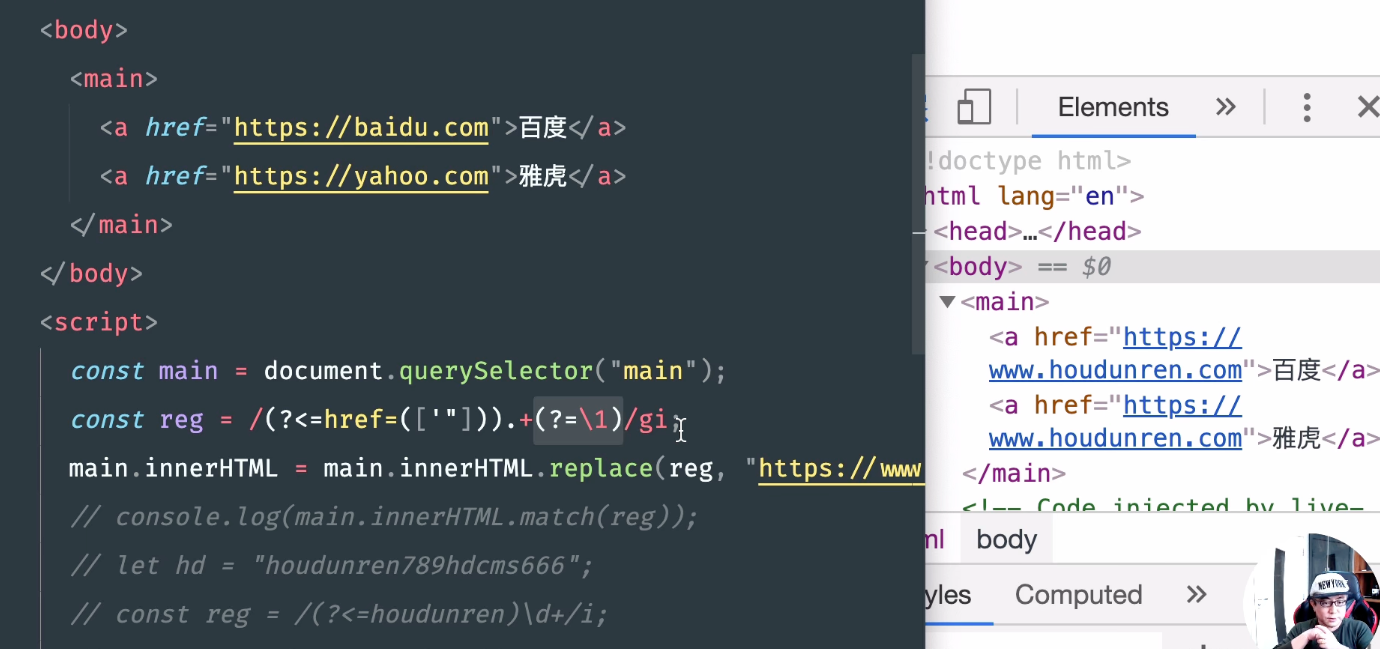
?<= //判断前面内容是..
?<=href= //前面是href="www.baidu.com"符合
?! //限制不是..
let reg = /[a-z]+(?!\d)$/i //限制最后一位不是数字
?! //限定不包含关键词,必须以字母结束
let reg = /^(?!.*百度.*)[a-z]{4,5}$/i
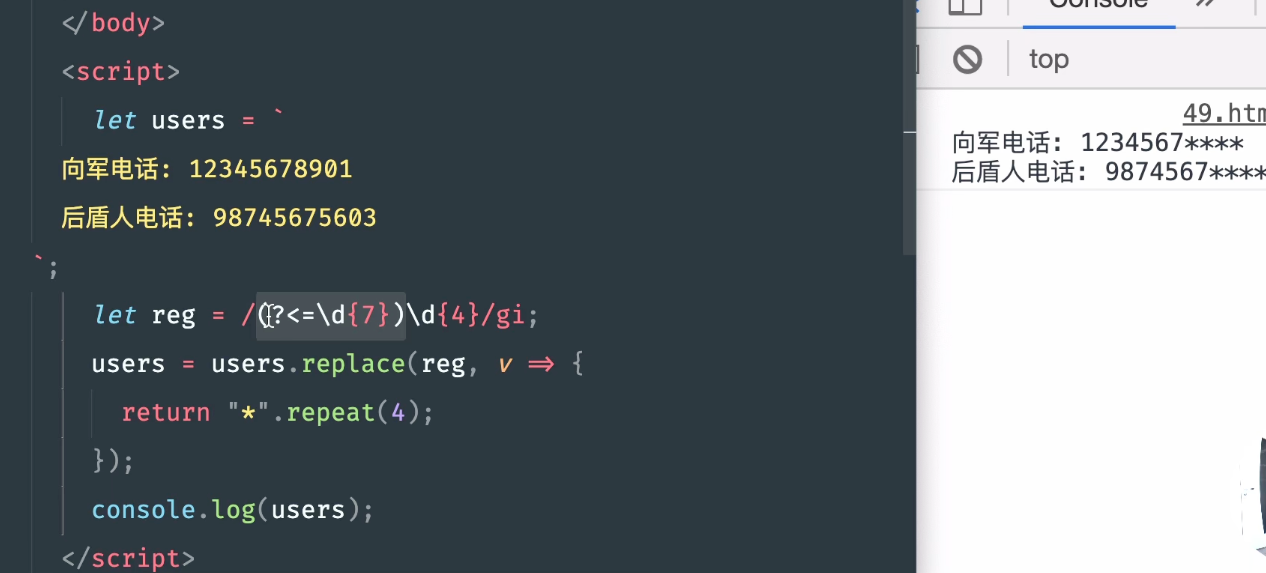
?<! //前面不是数字
let reg = /(?<!\d+)[a-z]+/i
'baidu88baidu'.match(reg) //baidu */